General Automatic Human Shape and Motion Capture
Using Volumetric Contour Cues
Abstract
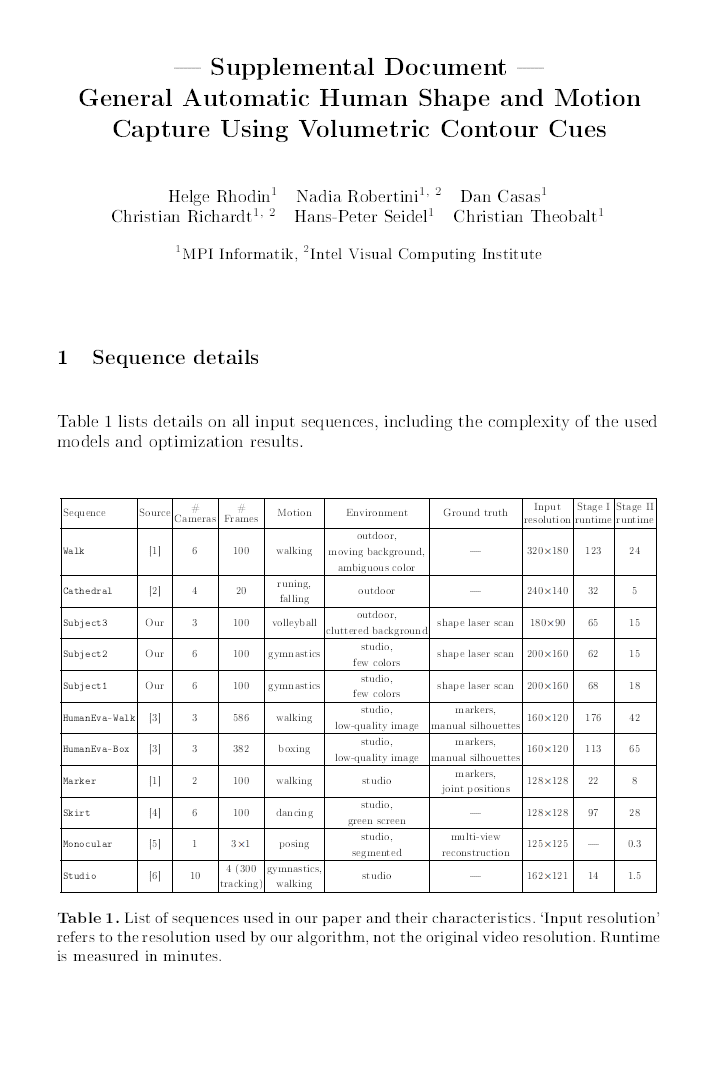
Markerless motion capture algorithms require a 3D body with properly personalized skeleton dimension and/or body shape and appearance to successfully track a person. Unfortunately, many tracking methods consider model personalization a different problem and use manual or semi-automatic model initialization, which greatly reduces applicability. In this paper, we propose a fully automatic algorithm that jointly creates a rigged actor model commonly used for animation -- skeleton, volumetric shape, appearance, and optionally a body surface -- and estimates the actor's motion from multi-view video input only. The approach is rigorously designed to work on footage of general outdoor scenes recorded with very few cameras and without background subtraction. Our method uses a new image formation model with analytic visibility and analytically differentiable alignment energy. For reconstruction, 3D body shape is approximated as a Gaussian density field. For pose and shape estimation, we minimize a new edge-based alignment energy inspired by volume ray casting in an absorbing medium. We further propose a new statistical human body model that represents the body surface, volumetric Gaussian density, and variability in skeleton shape. Given any multi-view sequence, our method jointly optimizes the pose and shape parameters of this model fully automatically in a spatiotemporal way.


Related Pages
Acknowledgments
We thank PerceptiveCode, in particular Arjun Jain and Jonathan Tompson, for providing and installing the ConvNet detector, Ahmed Elhayek, Jürgen Gall, Peng Guan, Hansung Kim, Armin Mustafa and Leonid Sigal for providing their data and test sequences, The Foundry for license support, and all our actors. This research was funded by the ERC Starting Grant project CapReal (335545).