Learning Complete 3D Morphable Face Models from Images and Videos
Abstract
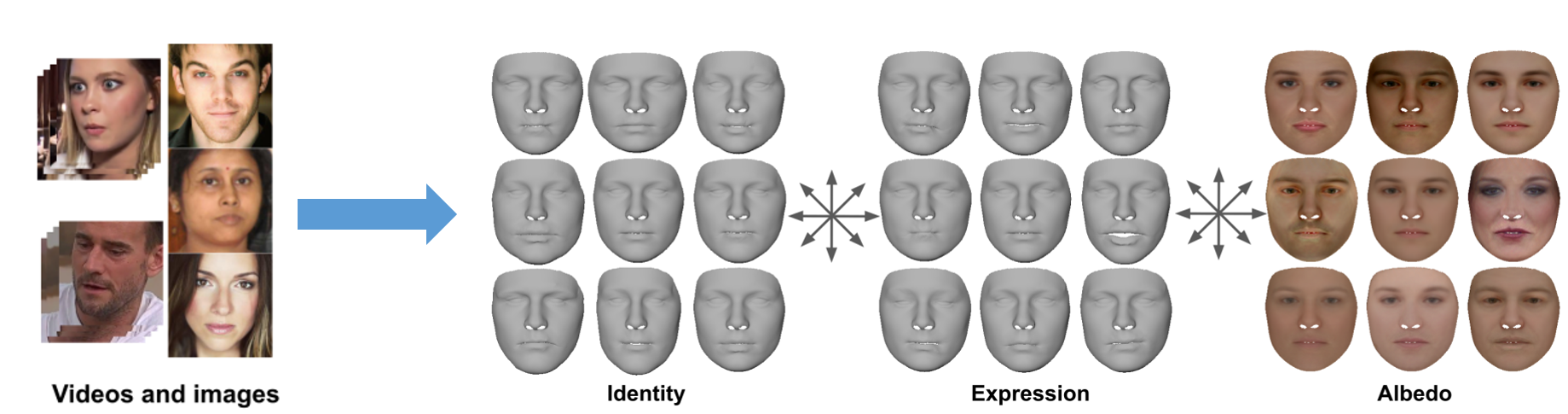
Most 3D face reconstruction methods rely on 3D morphable models, which disentangle the space of facial deformations into identity geometry, expressions and skin reflectance. These models are typically learned from a limited number of 3D scans and thus do not generalize well across different identities and expressions. We present the first approach to learn complete 3D models of face identity geometry, albedo and expression just from images and videos. The virtually endless collection of such data, in combination with our self-supervised learning-based approach allows for learning face models that generalize beyond the span of existing approaches. Our network design and loss functions ensure a disentangled parameterization of not only identity and albedo, but also, for the first time, an expression basis. Our method also allows for in-the-wild monocular reconstruction at test time. We show that our learned models better generalize and lead to higher quality image-based reconstructions than existing approaches.
Downloads

Citation
@inproceedings{mbr_CFML,
Author = {{B R}, Mallikarjun and Tewari, Ayush and Seidel, Hans-Peter and Elgharib, Mohamed and Theobalt, Christian},
Title = {Learning Complete 3D Morphable Face Models from Images and Videos},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2021}
}
Acknowledgments
This work was supported by the ERC Consolidator Grant 4DReply (770784).